Posts
Select Nth Highest Salary
select min (salary) from ( select distinct salary from emp order by salary desc ) where rownum < 3; In order to calculate the second highest salary use rownum < 3 In order to calculate the third highest salary use rownum < 4
Database Indexing
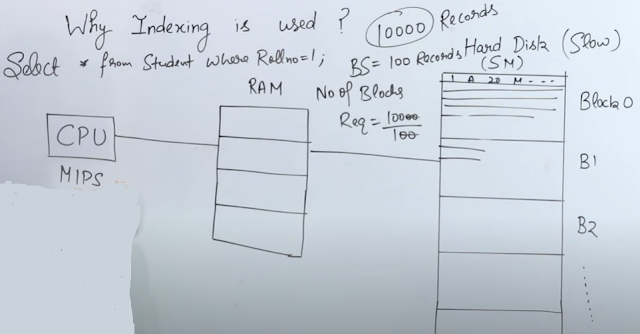
Database is divided into logical blocks and each block contains data. CPU works along with RAM. One by one Block loads into the RAM and CPU reads the block if the record is not found then another block will load into the memory. If we need to store 10000 records and 1 block can store 100 records. No. of blocks required = 10000/100->100 blocks. Indexing basically reduces the I/O cost means it reduces the number of blocks that get loaded in the RAM. Block Size -> 1000 Bytes Record Size -> 250 Bytes Total No of records -> 10000 Records in a block -> 1000/250-> 4 records Total No of blocks required -> 10000/4 -> 2500 Suppose it is taking 1 ms to read 1 block. In best case it will take -> 1 ms In worst case, it will be the last record -> 2500 ms Average Case -> 2500/2 = 1250 (N/2) If the data is sorted then we can implement binary search. Time Complexi...
Java 8 : Find the number starts with 1 from a list of integers
List<Integer> list = List. of ( 12 , 32 , 14 , 15 , 56 ); //Result->12,14,15 List<String> listString = list.stream().map(String::valueOf).collect(Collectors.toList()); List<String> result1 = listString.stream().filter(x->x.startsWith( "1" )) .collect(Collectors.toList()); System. out .println( "result1-->" +result1); List<String> result2 = list.stream().map(x->x+ "" ).filter(x->x.startsWith( "1" )) .collect(Collectors.toList()); System. out .println( "result2-->" +result2);
Construct Binary Tree from Preorder and Inorder Traversal

Given two integer arrays preorder and inorder where preorder is the preorder traversal of a binary tree and inorder is the inorder traversal of the same tree, construct and return the binary tree . Example 1: Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] Output: [3,9,20,null,null,15,7] Example 2: Input: preorder = [-1], inorder = [-1] Output: [-1]
1038. Binary Search Tree to Greater Sum Tree

Given the root of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST. As a reminder, a binary search tree is a tree that satisfies these constraints: The left subtree of a node contains only nodes with keys less than the node's key. The right subtree of a node contains only nodes with keys greater than the node's key. Both the left and right subtrees must also be binary search trees. Example 1: Input: root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8] Output: [30,36,21,36,35,26,15,null,null,null,33,null,null,null,8] Example 2: Input: root = [0,null,1] Output: [1,null,1] Solution class Solution { int pre = 0; public TreeNode bstToGst(TreeNode root) { if (root.right != null) bstToGst(root.right); pre = root.val = pre + root.val; if (root.left != null) bs...
Minimum Depth of a binary tree
class Solution { public int minDepth (TreeNode root) { if (root == null) return 0; if (root.left == null) return minDepth(root.right) + 1; if (root.right == null) return minDepth(root.left) + 1; return Math.min(minDepth(root.left),minDepth(root.right)) + 1; } }
Java 8 Default Method Added
It has been Quite a while since Java 8 released. With the release, they have improved some of the existing APIs and added few new features. One of them is forEach Method in java.lang.Iterable Interface. Whenever we need to traverse over a collection we have to create an Iterator to iterate over the collection and then we can have our business logic inside a loop for each of the elements inside the collection. We may greeted with ConcurrentModificationException if it is not implemented properly. The implementation of forEach method in Iterable interface is: default void forEach(Consumer action) { Objects.requireNonNull(action); for (T t : this) { action.accept(t); } } //Program 1 before Java 8 // Java program to demonstrate // forEach() method of Iterable interface public class ForEachExample { public static void main(String[] args) { Li...
Optional Vs Null Check

The purpose of Optional is not to replace every single null reference in your codebase but rather to help design better APIs in which—just by reading the signature of a method—users can tell whether to expect an optional value. In addition, Optional forces you to actively unwrap an Optional to deal with the absence of a value; as a result, you protect your code against unintended null pointer exceptions. String version = computer.getSoundcard().getUSB().getVersion(); This code can lead to NullPointerException. Handle NullPointerException - This code looks ugly. String version = "UNKNOWN"; if(computer != null){ Soundcard soundcard = computer.getSoundcard(); if(soundcard != null){ USB usb = soundcard.getUSB(); if(usb != null){ version = usb.getVersion(); } } } String name = computer.flatMap(Computer::getSoundcard) .f...
How to prevent Singleton Class from Reflection and Serialization

First create a singleton class. If we will try to clone it, it will throw Exception. Now try to break the Singleton with Reflection How to prevent Object Creation with Reflection - Check in the private constructor if object already created then throw an exception. If we run the reflection code, we will get this exception. Prevent Singleton Class from Serialization We have to override the read resolve method
Customized Immutable Class

Java Immutable Class In Java, when we create an object of an immutable class, we cannot change its value. For example, String is an immutable class. Hence, we cannot change the content of a string once created. Besides, we can also create our own custom immutable classes. Here's what we need to do to create an immutable class. declare the class as final so it cannot be extended all class members should be private so they cannot be accessed outside of class shouldn't contain any setter methods to change the value of class members the getter method should return the copy of class members class members are only initialized using constructor. PROS - Immutable Object is Threadsafe. For Constant Value. Used as a HashMap Key. (String, Integer, all wrapper classes are immutable) Why Hashmap key should be immutable? Immutability allows you to get same hash code every time, for a key object. So it actually solves most of the problems in one go. Also, this class must honor the hashCode() ...
Mapped Diagnostic Context (MDC) - Improved Java Logging
Mapped Diagnostic Context provides a way to enrich log messages with information that could be unavailable in the scope where the logging actually occurs but that can be indeed useful to better track the execution of the program. More detail, refer - https://www.baeldung.com/mdc-in-log4j-2-logback
Rest Template Vs Web Client
Since the REST era, most developers have become used to working with Spring’s traditional RestTemplate from the package spring-boot-starter-web for consuming Rest services. Spring also has a WebClient in its reactive package called spring-boot-starter-webflux. Since WebClient is supposed to be the successor of RestTemplate, we will be looking into it a bit deeper. RestTemplate provides a synchronous way of consuming Rest services, which means it will block the thread until it receives a response. RestTemplate is deprecated since Spring 5 which means it’s not really that future proof. WebClient exists since Spring 5 and provides an asynchronous way of consuming Rest services, which means it operates in a non-blocking way. WebClient is in the reactive WebFlux library and thus it uses the reactive streams approach. However, to really benefit from this, the entire throughput should be reactive end-to-end. Another benefit of working with Flux and Mono is that you can do mappings, filte...

How Service Discovery Works internally

A microservices-based application typically runs in virtualized or containerized environments. The number of instances of a service and its locations changes dynamically. We need to know where these instances are and their names to allow requests to arrive at the target microservice. This is where tactics such as Service Discovery come into play. The Service Discovery mechanism helps us know where each instance is located. In this way, a Service Discovery component acts as a registry in which the addresses of all instances are tracked. The instances have dynamically assigned network paths. Consequently, if a client wants to make a request to a service, it must use a Service Discovery mechanism. The Need for Service Discovery A microservice needs to know the location (IP address and port) of every service it communicates with. If we don’t employ a Service Discovery mechanism, service locations become coupled, leading to a system that’s difficult to maintain. We could wire the locations ...
RDS vs Aurora DB
1) Backtrack/Point in Time Restore (PITR) RDS Point in time restore is restore is supported, but it requires another RDS instance to be launched. Aurora Backtracks lets you quickly rewind the DB cluster to a specific point in time, without having to create another DB cluster. 2) Engine Options - Differences RDS - No concept of Global DB. Aurora - Global DB, Primary DB in one region and secondary DB in another region. 3) Compatibility with DB engines Aurora is compatible with two DBMSs namely PostgreSQL and MySQL. It is compatible with PostgreSQL 9.6.1 and MySQL 5.6. This means that you can run your existing database tools and applications on Aurora without any modifications. On the other hand, Amazon RDS requires you to use AWS Database Migration Service to migrate from EC2-hosted or on-premises databases such as MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle. 4) Failover In RDS, Failover to read replica is done manually, which could lead to data loss. You can ...
AWS Lamda Cold Start
AWS Lambda provides many benefits for developers, including scalability, flexibility, faster release times, and reduced cost. However, also comes with limitations such as cold starts. Cold starts can increase the latency of serverless applications How Does AWS Lambda Work? Lambda functions run on their own container. When you create a new function, Lambda packages it into a new container. This container is then executed on a multi-tenant cluster of managed machines. Before the functions start running, each container is allocated its necessary CPU and RAM capacity. When a function finishes running, the allocated RAM is multiplied by the amount of time the function spent running. AWS charges customers based on the allocated memory and the amount of function run time. AWS Lambda can simultaneously execute many instances of the same function, or of different functions from the same AWS account. This makes Lambda suitable for deploying highly scalable cloud computing solutions. What Is an A...

Right Rotation of an Array

Reversal algorithm for right rotation of an array Given an array, right rotate it by k elements. After K=3 rotation Examples: Input: arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} k = 3 Output: 8 9 10 1 2 3 4 5 6 7 Input: arr[] = {121, 232, 33, 43 ,5} k = 2 Output: 43 5 121 232 33 Note : In the below solution, k is assumed to be smaller than or equal to n. We can easily modify the solutions to handle larger k values by doing k = k % n Algorithm: rotate(arr[], d, n) reverse(arr[], 0, n-1) ; reverse(arr[], 0, d-1); reverse(arr[], d, n-1); // Java program for right rotation of // an array (Reversal Algorithm) import java.io.*; class Test { // Function to reverse arr[] // from index start to end static void reverseArray(int arr[], int start, int end) { while (start < end) { int temp = arr[start]; arr[start] = arr[end]; arr[end] = temp; start++; end--; } } // Function to right rotate // arr[] of size n b...
AWS Lamda

A WS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services. It is a computing service that runs code in response to events and automatically manages the computing resources required by that code. It was introduced in November 2014. No worries about the server - You don't require servers, all you need to do is write the code and upload it to lamda. Which means, you can stop worrying about provisioning and managing those servers. The only thing Lamda requires to work is your code. Automatic Scaling - Scaling is done automatically based on the size of the workload. It scales the application running the code in response to each trigger. Metering on the second - You only pay for the amount of time that your code is running. Which means that you are not charged for any of the servers. The only payment required is for the amount of time the code is computed. AWS Lamda is one of the services that falls under the 'Compute' doma...