Understanding Database Internals with PostgreSQL: From Seq Scan to Index Scan
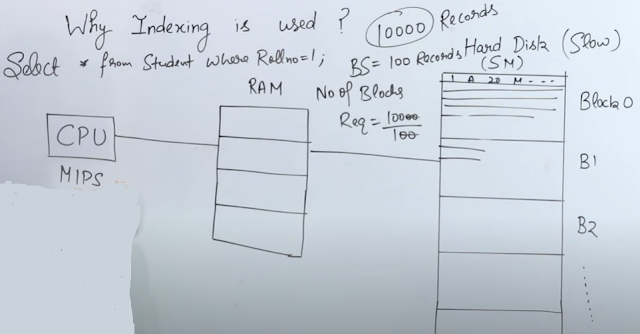
When working with databases in real-world systems, one of the most common performance issues is slow queries . Many developers rely on trial-and-error fixes, but understanding how the database actually executes queries is what truly differentiates an average engineer from a strong one. In this article, we’ll walk through key database internals using PostgreSQL — covering execution plans, index usage, and core architectural concepts. Getting Started: What is an Execution Plan? When you run a query, the database doesn’t execute it directly. Instead, it goes through: SQL → Parser → Optimizer → Execution Engine The optimizer decides how to execute your query efficiently. To see this decision, we use: EXPLAIN SELECT * FROM test."Employee"; Sequential Scan (Seq Scan) Example output: Seq Scan on "Employee" (cost=0.00..1736.00 rows=100000 width=27) What does this mean? Seq Scan → Database scans entire table row by row cost → Estimated effort (not actual time) rows ...